How to Win a Data Science Competition
How to Win a Data Science Competition: Learn from Top Kagglers
linear model:适合高维稀疏线性可分空间
decision tree: 难以捕捉线性相关性,分成boxes
k-NN:
NN:非线性边界
Tips
1. feature preprocessing
类别数据:
- one hot encoding
- 随机森林不用transform类别数据
numeric features:
scale
- tree model不用变形数据
- 其他可能要变
- scale可能影响梯度下降有效性
- minmaxscaling
- standardscaler
- 有时可以适当放缩feature,来看模型有没有变好,这样使得那个feature更重要
outlier:
- 可以选择上下界(按照百分比)
- winsorization:对financial data
- 可以看直方图
- 可以选择上下界(按照百分比)
rank
- 线性模型、knn、nn对于这个处理方式有效
- scipy.stats.rankdata
对于non-tree based models:
- log transform
- 开根号:np.sqrt(x+2/3)
- 减少异常值,增大0附近差异
- 可以混合不同模型(基于不同的处理方法)
feature generation:
- 加减乘除
- 取小数部分
- 要理解数据
categorical features/ ordinal features
label encoding
对tree友好
要转化为数字
按字母排序:sklearn.preprocessing.LabelEncode
按出现顺序:pandas.factorize
转化为出现频率作为特征(常用于tree)
1
2
3encoding = titanic.groupby('Embarked').size()
encoding = encoding/len(titanic)
titanic['enc'] = titanic.Embarked.map(encoding)rank
1
from scipy.stats import rankdata
one hot encoding:常用于non-tree
- pandas.get_dummies
- sklearn.preprocessing.OneHotEncoder
- 可能对tree不友好
- 需要稀疏矩阵(word)
- 组合各种类别,形成多种类:如等级加性别
Datetime
- 周期
- 时间点
- 时间跨度(距离过去,距离未来)
坐标coordination
- 单坐标
- 区域中心
- 特殊位置
- 统计值
- 区域统计值
- 距离
- 旋转坐标可能有奇效
- 单坐标
missing values
- fillna
- -999,-1
- 注意在后面均一化时会有重大影响
- feature generation前 fillna可能有问题
- 中位数、均值
- reconstruct value
- 时间序列:estimation
- 其他的很难估计
- -999,-1
- 添加一个isNull的feature,神经网络和tree
- 可以把outlier as missing values
- xgboost可以处理nan
- fillna
text
bag of words
sklearn.feature_extraction.text.CountVectorizer
TF-iDF
term frequency
inverse document frequency
1
2
3
4
5tf = 1/x.sum(axis=1)[:,None]
x = x*tf
idf = np.log(x.shape[0]/(x>0).sum(0))
x = x*idf
# sklearn.feature_extraction.text.TfidfVectorizer可以降低高频词比重
N-grams
- n个字符组合
- sklearn.feature_extraction.text.CountVectorizer: Ngram_range, analyzer
lowercase
lemmatization: car = cars转换为基本形式
stemming: 取词干
stopwords:
- NLTK: natural language toolkit library
- sklearn.feature_extraction.text.CountVectorizer: max_df(按频率删除)
embedding(word2vec)
- 邻近的词向量相近:向量相加减, 几百个维度
- Word2vec, Glove, FastText
- Doc2vec
- pretrained model
image
- CNN
- 预先训练好的模型微调fine-tuning再训练对小数据集有时候很有效
- keras等库有
- image augmentation:
- 旋转图像,增加样本
- 加噪音
2. EDA
- 查看数据逻辑,检查是否有error,探究error原因
- 了解数据如何被采集,可以有效设置validation scheme
- plt.hist(x)
- plt.plot(x)
- plt.scatter(len(x), x, c=y)
- x.describe
- look at pairs/groups
- 检查train test是否分布相同
- 根据eda结果生成新feature
- pd.scatter_matrix(df)
- plt.matshow()
- sort_values
- 检查重复的特征或常数特征(drop_duplicate)
- traintest[f] = traintest[f].factorize()
- .select_dtypes(include=['object'])可以选择不同类型columns
3. Validation and overfitting
validation:
holdout: sklearn.model_selection.ShuffleSplit
k fold: sklearn.model_selection.Kfold
leave one out: sklearn.model_selection.LeaveOneOut
Stratification: 分层,保留相同分布
Data splitting:
- random: row independent
- time-based splits
- moving window validation: sklearn.model_selection.TimeSeriesSplit
- by id
- combined
- https://medium.com/@soumyachess1496/cross-validation-in-time-series-566ae4981ce4
- 有时需要看test set和train的分布差异
data leak:
- time series
4. metrics evaluation
regression metrics:
可以改loss function:

MSE: 常数的最优估计是均值
RMSE:root mean square error
R-squared
MAE: mean average error: not sensetive than mse to outlier
- 常数的最优估计是median
- 对outlier友好
- XGBoost不能用,因为二阶导为0
- LightGBM可以用
- 类似huber loss:特别是当error比较大
- 常数的最优估计是median
MSPE:
- 常数的最优估计是weighted target mean
MAPE:
- 常数最优估计:weighted target median
- outlier会有很高权重,很少用
RMSLE:log space
classification metric:
- accuracy
- log loss
- binary
- multi loss
- AUC:area under curve,包括order
- ROC
- cohen‘s Kappa
- confusion matrix
- weighted error
- quadratic and linear weighted kappa:多用于医学
optimization
有的模型不能用一些loss function来优化:
XGBoost不能用MSPE
custom loss for XGBoost:
1
2
3
4
5def logregobj(preds,dtrains):
labels = dtrain.get_label()
preds = 1.0/(1.0+np.exp(-preds))# 有时要处理pred
grad = preds - labels
hess = preds * (1.0-preds)
early stopping: 防止overfitting
变换target:比如指数、log等
calibrate prediction
- plat scaling: fit logistic regression to predictions(stacking)
- isotonic regression: fit isotonic regression to predictions
- stacking: fit XGBoost or neural net to predictions
AUC(ROC) optimization:
pointwise loss: \(\min \Sigma L_{point}(\hat y_i;y_i)\)
pairwise loss:
\(\min \Sigma L_{pair}(\hat y_i,\hat y_j:y_i,y_j)\)
\[ \operatorname{Loss}=-\frac{1}{N_{0} N_{2}} \sum_{j: y_{j}=1}^{N_{1}} \sum_{i: y_{i}=0}^{N_{0}} \log \left(\operatorname{prob}\left(\hat{y}_{j}-\hat{y}_{i}\right)\right) \]
xgboost, lightboom可行
quadratic weighted Kappa:
optimize MSE
\[ \begin{aligned} \operatorname{Kappa}(y, \hat{y}) & \approx 1-\frac{\frac{1}{N} \sum_{i=1}^{N}\left(\hat{y}_{i}-y_{i}\right)^{2}}{\text { hard to deal with part }} \\ &=1-\frac{\operatorname{MSE}(y, \hat{y})}{\text { hard to deal with part }} \end{aligned} \]
optimize thresholds
mean encoding: 有很多分类特征
StratifiedKFold
分析树可能有新发现

5. hyper parameter tuning
- libraries:
- hyperopt
- scikit-optimize
- spearmint
- gpyopt
- robo
- smac3
- GBDT
绿色提升fit,红色降低fit
min_child_weight很重要,increase model变保守(0,5,15,300……)
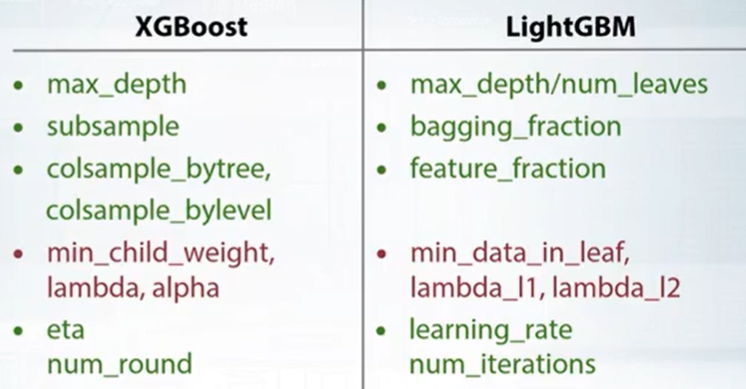
sklearn.randomforest/ExtraTrees
- N_estimators(higher the better)

- neural networks
- 可以将数据存储为HDF5或MPI格式,或cpickle

6. pipeline
- EDA:
- histgram
- feature vs target
- univariate predictability metrics(IV,R,auc)
- bining numerical features and correlation matrices
- Decide the CV strategy
- feature engineering:
- Modeling

看文献
- Ensemble
7. feaure
- bray-curtis metric
- KNN features
- matrix factorization: 利用矩阵分解、加减乘除来增加、减少feature
- feature interactions:
- f1 and f2: 组合形成one hot矩阵:先各自one hot,再pairwise相乘
- 积分、微分
- 可以用random forest来选择feature importance
- 分析树的结构创造新特征:
- xgboost:predict(pred_leaf=True)
- sklearn: apply()
- tSNE
- 常用于EDA
- great tool for visualization
- 但是要调参
- dstill.pub 学习网站
- library: tsne, sklearn(慢)
- 结果可能不容易理解
8. Ensemble
- bagging:
- sklearn: baggingClassifier, BaggingRegressor
- boosting:
- weight based boosting: 关注错的更厉害的
- adaboost
- residual based boosting
- learning rate
- num of estimator
- models:
- dart:只用之前一部分模型的预测结果
- fully gradient based
- xgboost
- lightgbm
- catboost
- sklearn GBM
- weight based boosting: 关注错的更厉害的
- stacking:
用所有模型的predict输入到新模型
注意time
stacknet
- 可以用Kfold形式训练各个模型
- 可以把原始feature加入stacking


小心data leakage
stacknet:可用从说明文档中学习到各个模型哪些参数重要
xcessiv
stacked ensembles from h2o
- catboost
- 快,预制了很多函数
- overfiting detector